
Evolutionary Multi-Objective Optimization
Luis Martí (LIRA/DEE/PUC-Rio)
http://lmarti.com; lmarti@ele.puc-rio.br
Programa de Verão 2015 - Laboratório Nacional de Computação Científica
In this talk
- Multi-objective optimization problems (MOPs).
- "Classical" (mathematical) approaches.
- Challanges of evolutionary computation to solve MOPs?
- The Non-dominated Sorting Genetic Algorithm II (NSGA-II).
- Benchmark test problems.
- Experiment design and comparing results.
- Salient issues.
About the slides

- You may notice that I will be running some code inside the slides.
- That is because the slides are programmed as a IPython notebook.
- If you are viewing this as a "plain" notebook, be warned that the slide version is the best way of viewing it.
- You can get them from https://github.com/lmarti/emo-course-lncc.
- You are free to try them and experiment on your own.
For the slides we need to import some required modules:
import time, array, random, copy, math
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
How can we handle multiple -and possibly conflicting- objectives?
It's "easy": we do it all the time.
 taken from http://xkcd.com/388/
taken from http://xkcd.com/388/Multi-objective optimization
- Most -if not all- optimization problems involve more than one objective function to be optimized simultaneously.
- For example, you must optimize a given feature of an object while keeping under control the resources needed to elaborate that object.
- Sometimes those other objectives are converted to constraints or fixed to default values, but they are still there.
- Multi-objective optimization is also known as multi-objective programming, vector optimization, multicriteria optimization, multiattribute optimization or Pareto optimization (and probably by other names, depending on the field).
- Multi-objective optimization has been applied in many fields of science where optimal decisions need to be taken in the presence of trade-offs between two or more conflicting objectives.
A Multi-objective Optimization Problem (MOP)
$$ \renewcommand{\vec}[1]{\mathbf{#1}} \newcommand{\set}[1]{\mathcal{#1}} \newcommand{\dom}{\preccurlyeq} \begin{array}{rl} \mathrm{minimize} & \vec{F}(\vec{x})=\langle f_1(\vec{x}),\ldots,f_M(\vec{x})\rangle\,,\\ \mathrm{subject}\ \mathrm{to} & c_1(\vec{x}),\ldots,c_C(\vec{x})\le 0\,,\\ & d_1(\vec{x}),\ldots,d_D(\vec{x})= 0\,,\\ & \text{with}\ \vec{x}\in\set{D}\,, \end{array} $$
- $\mathcal{D}$ is known as the decision set or search set.
- functions $f_1(\mathbf{x}),\ldots,f_M(\mathbf{x})$ are the objective functions. If $M=1$ the problem reduces to a single-objective optimization problem.
- Image set, $\set{O}$, result of the projection of $\set{D}$ via $f_1(\vec{x}),\ldots,f_M(\vec{x})$ is called objective set ($\vec{F}:\set{D}\rightarrow\set{O}$).
- $c_1(\vec{x}),\ldots,c_C(\vec{x})\le 0$ and $d_1(\vec{x}),\ldots,d_D(\vec{x})= 0$ express the constraints imposed on the values of $\vec{x}$.
Note: In case you are -still- wondering, a maximization problem can be posed as the minimization one: $\min\ -\vec{F}(\vec{x})$.
Example: A two variables and two objectives MOP
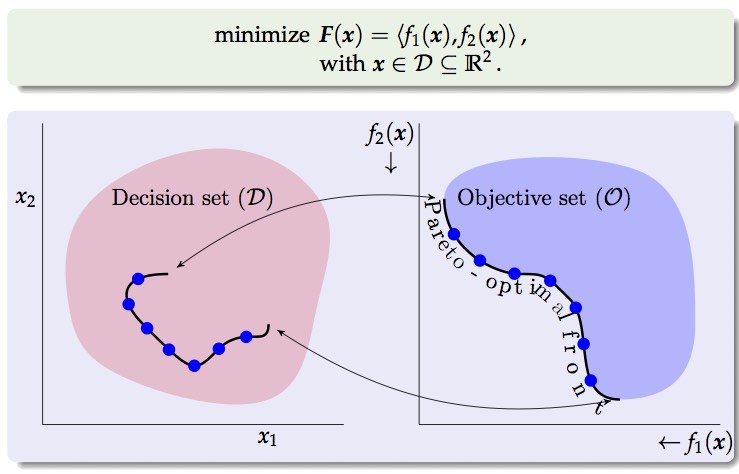
MOP (optimal) solutions
Usually, there is not a unique solution that minimizes all objective functions simultaneously, but, instead, a set of equally good trade-off solutions.
- Optimality can be defined in terms of the Pareto dominance relation.
- That is, having $\vec{x},\vec{y}\in\set{D}$, $\vec{x}$ is said to dominate $\vec{y}$ (expressed as $\vec{x}\dom\vec{y}$) iff $\forall f_j$, $f_j(\vec{x})\leq f_j(\vec{y})$ and $\exists f_i$ such that $f_i(\vec{x})< f_i(\vec{y})$.
- Having the set $\set{A}$. $\set{A}^\ast$, the non-dominated subset of $\set{A}$, is defined as
$$ \set{A}^\ast=\left\{ \vec{x}\in\set{A} \left|\not\exists\vec{y}\in\set{A}:\vec{y}\dom\vec{x}\right.\right\}. $$
- The Pareto-optimal set, $\set{D}^{\ast}$, is the solution of the problem. It is the subset of non-dominated elements of $\set{D}$. It is also known as the efficient set.
- It consists of solutions that cannot be improved in any of the objectives without degrading at least one of the other objectives.
- Its image in objective set is called the Pareto-optimal front, $\set{O}^\ast$.
- Evolutionary algorithms generally yield a set of non-dominated solutions, $\set{P}^\ast$, that approximates $\set{D}^{\ast}$.
Visualizing the Pareto dominance relation
from deap import algorithms, base, benchmarks, tools, creator
Planting a constant seed to always have the same results (and avoid surprises in class). -you should not do this in a real-world case!
random.seed(a=42)
- To start, lets have a visual example of the Pareto dominance relationship in action.
- In this notebook we will deal with two-objective problems in order to simplify visualization.
- Therefore, we can create:
creator.create("FitnessMin", base.Fitness, weights=(-1.0,-1.0))
creator.create("Individual", array.array, typecode='d',
fitness=creator.FitnessMin)
Let's use an illustrative MOP problem: Dent
$$ \begin{array}{rl} \text{minimize} & f_1(\vec{x}),f_2(\vec{x}) \\ \text{such that} & f_1(\vec{x}) = \frac{1}{2}\left( \sqrt{1 + (x_1 + x_2)^2} \sqrt{1 + (x_1 - x_2)^2} + x_1 -x_2\right) + d,\\ & f_2(\vec{x}) = \frac{1}{2}\left( \sqrt{1 + (x_1 + x_2)^2} \sqrt{1 + (x_1 - x_2)^2} - x_1 -x_2\right) + d,\\ \text{with}& d = \lambda e^{-\left(x_1-x_2\right)^2}\ (\text{generally }\lambda=0.85) \text{ and } \vec{x}\in \left[-1.5,1.5\right]^2. \end{array} $$
Implementing the Dent problem
def dent(individual, lbda = 0.85):
"""
Implements the test problem Dent
Num. variables = 2; bounds in [-1.5, 1.5]; num. objetives = 2.
@author Cesar Revelo
"""
d = lbda * math.exp(-(individual[0] - individual[1]) ** 2)
f1 = 0.5 * (math.sqrt(1 + (individual[0] + individual[1]) ** 2) + \
math.sqrt(1 + (individual[0] - individual[1]) ** 2) + \
individual[0] - individual[1]) + d
f2 = 0.5 * (math.sqrt(1 + (individual[0] + individual[1]) ** 2) + \
math.sqrt(1 + (individual[0] - individual[1]) ** 2) - \
individual[0] + individual[1]) + d
return f1, f2
Preparing a DEAP toolbox with Dent.
toolbox = base.Toolbox()
BOUND_LOW, BOUND_UP = -1.5, 1.5
NDIM = 2
# toolbox.register("evaluate", lambda ind: benchmarks.dtlz2(ind, 2))
toolbox.register("evaluate", dent)
Defining attributes, individuals and population.
def uniform(low, up, size=None):
try:
return [random.uniform(a, b) for a, b in zip(low, up)]
except TypeError:
return [random.uniform(a, b) for a, b in zip([low] * size, [up] * size)]
toolbox.register("attr_float", uniform, BOUND_LOW, BOUND_UP, NDIM)
toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.attr_float)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
Creating an example population distributed as a mesh.
num_samples = 50
limits = [np.arange(BOUND_LOW, BOUND_UP, (BOUND_UP - BOUND_LOW)/num_samples)] * NDIM
sample_x = np.meshgrid(*limits)
flat = []
for i in range(len(sample_x)):
x_i = sample_x[i]
flat.append(x_i.reshape(num_samples**NDIM))
example_pop = toolbox.population(n=num_samples**NDIM)
for i, ind in enumerate(example_pop):
for j in range(len(flat)):
ind[j] = flat[j][i]
fitnesses = toolbox.map(toolbox.evaluate, example_pop)
for ind, fit in zip(example_pop, fitnesses):
ind.fitness.values = fit
Visualizing Dent
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
for ind in example_pop: plt.plot(ind[0], ind[1], 'k.', ms=3)
plt.xlabel('$x_1$');plt.ylabel('$x_2$');plt.title('Decision space');
plt.subplot(1,2,2)
for ind in example_pop: plt.plot(ind.fitness.values[0], ind.fitness.values[1], 'k.', ms=3)
plt.xlabel('$f_1(\mathbf{x})$');plt.ylabel('$f_2(\mathbf{x})$');
plt.xlim((0.5,3.6));plt.ylim((0.5,3.6)); plt.title('Objective space');

We also need a_given_individual.
a_given_individual = toolbox.population(n=1)[0]
a_given_individual[0] = 0.5
a_given_individual[1] = 0.5
a_given_individual.fitness.values = toolbox.evaluate(a_given_individual)
Implementing the Pareto dominance relation between two individulas.
def pareto_dominance(ind1,ind2):
'Returns `True` if `ind1` dominates `ind2`.'
extrictly_better = False
for item1 in ind1.fitness.values:
for item2 in ind2.fitness.values:
if item1 > item2:
return False
if not extrictly_better and item1 < item2:
extrictly_better = True
return extrictly_better
Note: Bear in mind that DEAP implements a Pareto dominance relation that probably is more efficient than this implementation. The previous function would be something like:
def efficient_pareto_dominance(ind1, ind2):
return tools.emo.isDominated(ind1.fitness.values, ind2.fitness.values)
Lets compute the set of individuals that are dominated by a_given_individual, the ones that dominate it (its dominators) and the remaining ones.
dominated = [ind for ind in example_pop if pareto_dominance(a_given_individual, ind)]
dominators = [ind for ind in example_pop if pareto_dominance(ind, a_given_individual)]
others = [ind for ind in example_pop if not ind in dominated and not ind in dominators]
def plot_dent():
'Plots the points in decision and objective spaces.'
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
for ind in dominators: plt.plot(ind[0], ind[1], 'r.')
for ind in dominated: plt.plot(ind[0], ind[1], 'g.')
for ind in others: plt.plot(ind[0], ind[1], 'k.', ms=3)
plt.plot(a_given_individual[0], a_given_individual[1], 'bo', ms=6);
plt.xlabel('$x_1$');plt.ylabel('$x_2$');
plt.title('Decision space');
plt.subplot(1,2,2)
for ind in dominators: plt.plot(ind.fitness.values[0], ind.fitness.values[1], 'r.', alpha=0.7)
for ind in dominated: plt.plot(ind.fitness.values[0], ind.fitness.values[1], 'g.', alpha=0.7)
for ind in others: plt.plot(ind.fitness.values[0], ind.fitness.values[1], 'k.', alpha=0.7, ms=3)
plt.plot(a_given_individual.fitness.values[0], a_given_individual.fitness.values[1], 'bo', ms=6);
plt.xlabel('$f_1(\mathbf{x})$');plt.ylabel('$f_2(\mathbf{x})$');
plt.xlim((0.5,3.6));plt.ylim((0.5,3.6));
plt.title('Objective space');
plt.tight_layout()
Having a_given_individual (blue dot) we can now plot those that are dominated by it (in green), those that dominate it (in red) and those that are uncomparable.
plot_dent()

Obtaining the nondominated front.
non_dom = tools.sortNondominated(example_pop, k=len(example_pop),
first_front_only=True)[0]
plt.figure(figsize=(5,5))
for ind in example_pop:
plt.plot(ind.fitness.values[0], ind.fitness.values[1], 'k.', ms=3, alpha=0.5)
for ind in non_dom:
plt.plot(ind.fitness.values[0], ind.fitness.values[1], 'bo', alpha=0.74, ms=5)

So, is this the end?
- Ok, now we know how to solve MOPs by sampling the search space.
- MOPs, in the general case are NP-hard problems.
- Brute force is never the solution in just a-little-more-complex cases.
An example, solving the TSP problem using brute force:
| $n$ cities | time |
|---|---|
| 10 | 3 secs |
| 12 | 3 secs × 12 × 11 = 6.6 mins |
| 14 | 6.6 mins × 13 × 14 = 20 hours |
| 24 | 3 secs × 24! / 10! = 16 billion years |
Note: See my PhD EC course notebooks https://github.com/lmarti/evolutionary-computation-course for a notebook on solving the TSP problem using evolutionary algorithms.
Preference-based alternatives
- A Decision Maker can define a set of weights $w_1,\ldots,w_M$ for each function $f_1(),\ldots,f_M()$.
- We can convert a MOP into a SOP:
$$ \begin{array}{rl} \mathrm{minimize} & F(\vec{x})= w_1f_1(\vec{x})+\cdots + w_if_i(\vec{x}) +\cdots +w_Mf_M(\vec{x})\,,\\ \mathrm{subject}\ \mathrm{to} & c_1(\vec{x}),\ldots,c_C(\vec{x})\le 0\,,\\ & d_1(\vec{x}),\ldots,d_D(\vec{x})= 0\,,\\ & \text{with}\ \vec{x}\in\set{D}\,, \end{array} $$
- A single-objective optimizer $\implies$ only one solution not the complete PF.
- "Classical" (mathematicas programming) approaches use this method.
- Requires (a lot) of a priori knowledge.
- Relatively simple.
The Decision Maker
Lexicographical ordering of the objectives
 |
All objectives are important......but some objectives are more important than others. |
Better idea: Use the Pareto dominance relation to guide the search
- We can use the Pareto dominance relation to determine how good an individual is.
Ideas:
- For a solution $\vec{x}$, how many individuals dominate $\vec{x}$?
- ... and how many $\vec{x}$ dominates?
This looks like the perfect task for an evolutionary algorithm.
Evolutionary Algorithms
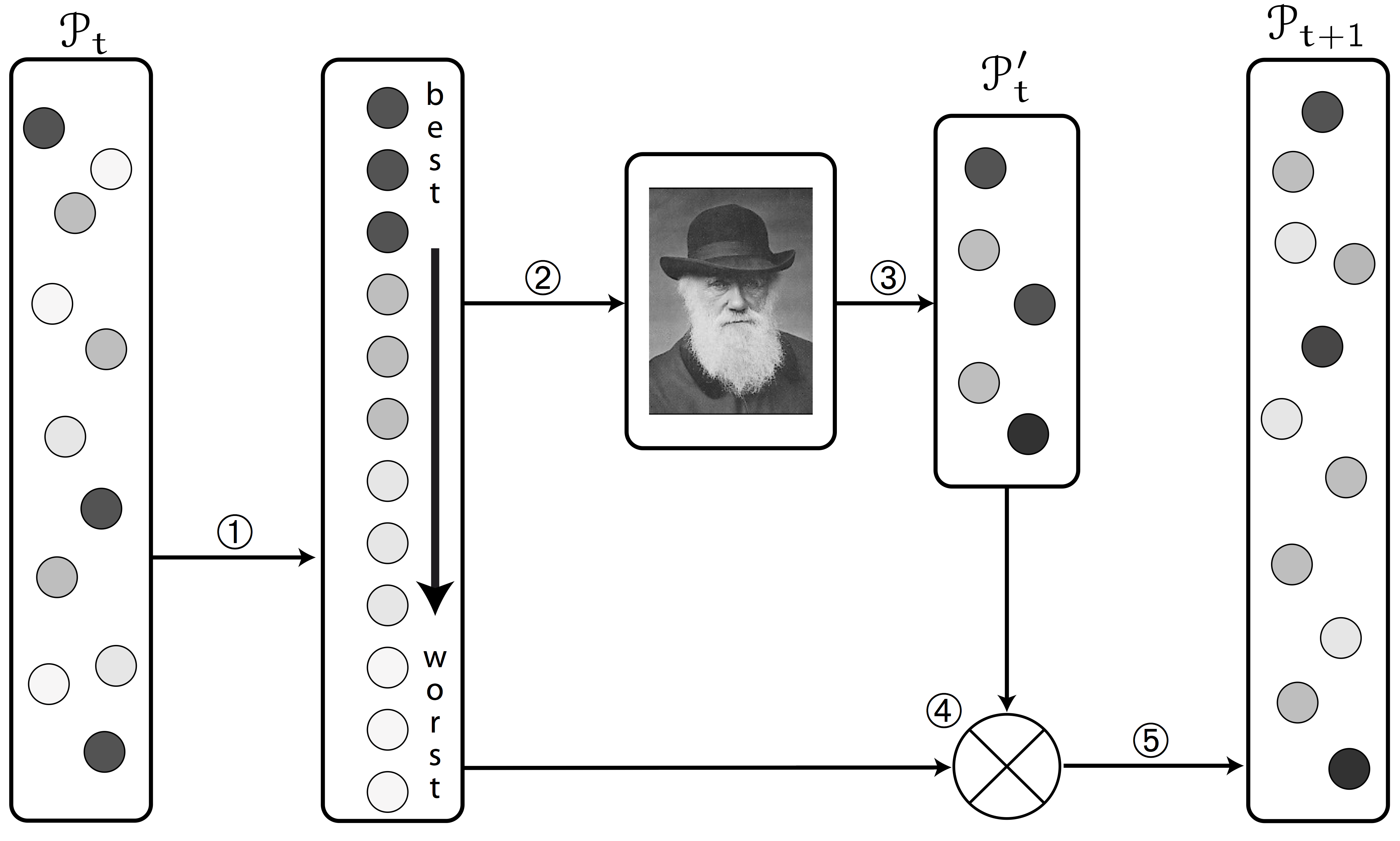
Mating selection + Variation (Offsping generation) + Enviromental selection $\implies$ global + local parallel search features.
Elements to take into account using evolutionary algorithms
- Individual representation (binary, Gray, floating-point, etc.);
- evaluation and fitness assignment;
- mating selection, that establishes a partial order of individuals in the population using their fitness function value as reference and determines the degree at which individuals in the population will take part in the generation of new (offspring) individuals.
- variation, that applies a range of evolution-inspired operators, like crossover, mutation, etc., to synthesize offspring individuals from the current (parent) population. This process is supposed to prime the fittest individuals so they play a bigger role in the generation of the offspring.
- environmental selection, that merges the parent and offspring individuals to produce the population that will be used in the next iteration. This process often involves the deletion of some individuals using a given criterion in order to keep the amount of individuals bellow a certain threshold.
- stopping criterion, that determines when the algorithm should be stopped, either because the optimum was reach or because the optimization process is not progressing.
Pseudocode of an evolutionary algorithm
def evolutionary_algorithm():
populations = [] # a list with all the populations
populations[0] = initialize_population(pop_size)
t = 0
while not stop_criterion(populations[t]):
fitnesses = evaluate(populations[t])
offspring = matting_and_variation(populations[t],
fitnesses)
populations[t+1] = environmental_selection(
populations[t],
offspring)
t = t+1
The Non-dominated Sorting Genetic Algorithm (NSGA-II)
- NSGA-II algorithm is one of the pillars of the EMO field.
- Deb, K., Pratap, A., Agarwal, S., Meyarivan, T., A fast and elitist multiobjective genetic algorithm: NSGA-II, IEEE Transactions on Evolutionary Computation, vol.6, no.2, pp.182,197, Apr 2002 doi: 10.1109/4235.996017.
- Fitness assignment relies on the Pareto dominance relation:
- Rank individuals according the dominance relations established between them.
- Individuals with the same domination rank are then compared using a local crowding distance.
NSGA-II fitness assigment in detail
- The first step consists in classifying the individuals in a series of categories $\mathcal{F}_1,\ldots,\mathcal{F}_L$.
Each of these categories store individuals that are only dominated by the elements of the previous categories, $$ \begin{array}{rl} \forall \vec{x}\in\set{F}_i: &\exists \vec{y}\in\set{F}_{i-1} \text{ such that } \vec{y}\dom\vec{x},\text{ and }\\ &\not\exists\vec{z}\in \set{P}_t\setminus\left( \set{F}_1\cup\ldots\cup\set{F}_{i-1} \right)\text{ that }\vec{z}\dom\vec{x}\,; \end{array} $$ with $\mathcal{F}_1$ equal to $\mathcal{P}_t^\ast$, the set of non-dominated individuals of $\mathcal{P}_t$.
After all individuals are ranked a local crowding distance is assigned to them.
- The use of this distance primes individuals more isolated with respect to others.
Crowding distance
The assignment process goes as follows,
- for each category set $\set{F}_l$, having $f_l=|\set{F}_l|$,
- for each individual $\vec{x}_i\in\set{F}_l$, set $d_{i}=0$.
- for each objective function $m=1,\ldots,M$,
- $\vec{I}=\mathrm{sort}\left(\set{F}_l,m\right)$ (generate index vector).
- $d_{I_1}^{(l)}=d_{I_{f_l}}^{(l)}=\infty$. (this is the key element)
- for $i=2,\ldots,f_l-1$,
- Update the remaining distances as, $$ d_i = d_i + \frac{f_m\left(\vec{x}_{I_{i+1}}\right)-f_m\left(\vec{x}_{I_{i+1}}\right)} {f_m\left(\vec{x}_{I_{1}}\right)-f_m\left(\vec{x}_{I_{f_l}}\right)}\,. $$
Here the $\mathrm{sort}\left(\set{F},m\right)$ function produces an ordered index vector $\vec{I}$ with respect to objective function $m$.
Sorting the population by rank and distance.
- Having the individual ranks and their local distances they are sorted using the crowded comparison operator, stated as:
- An individual $\vec{x}_i$ is better than $\vec{x}_j$ if:
- $\vec{x}_i$ has a better rank: $\vec{x}_i\in\set{F}_k$, $\vec{x}_j\in\set{F}_l$ and $k<l$, or;
- if $k=l$ and $d_i>d_j$.
- An individual $\vec{x}_i$ is better than $\vec{x}_j$ if:
Now we have key element of the the non-dominated sorting GA.
Implementing NSGA-II
We will deal with DTLZ3, which is a more difficult test problem.
- DTLZ problems can be configured to have as many objectives as desired, but as we want to visualize results we will stick to two objectives.
- DTLZ3 is a (more complex) version of DTLZ2.
- The Pareto-optimal front of DTLZ3 lies in the first orthant of a unit (radius 1) hypersphere located at the coordinate origin ($\vec{0}$).
- It has many local optima that run parallel to the global optima and render the optimization process more complicated.
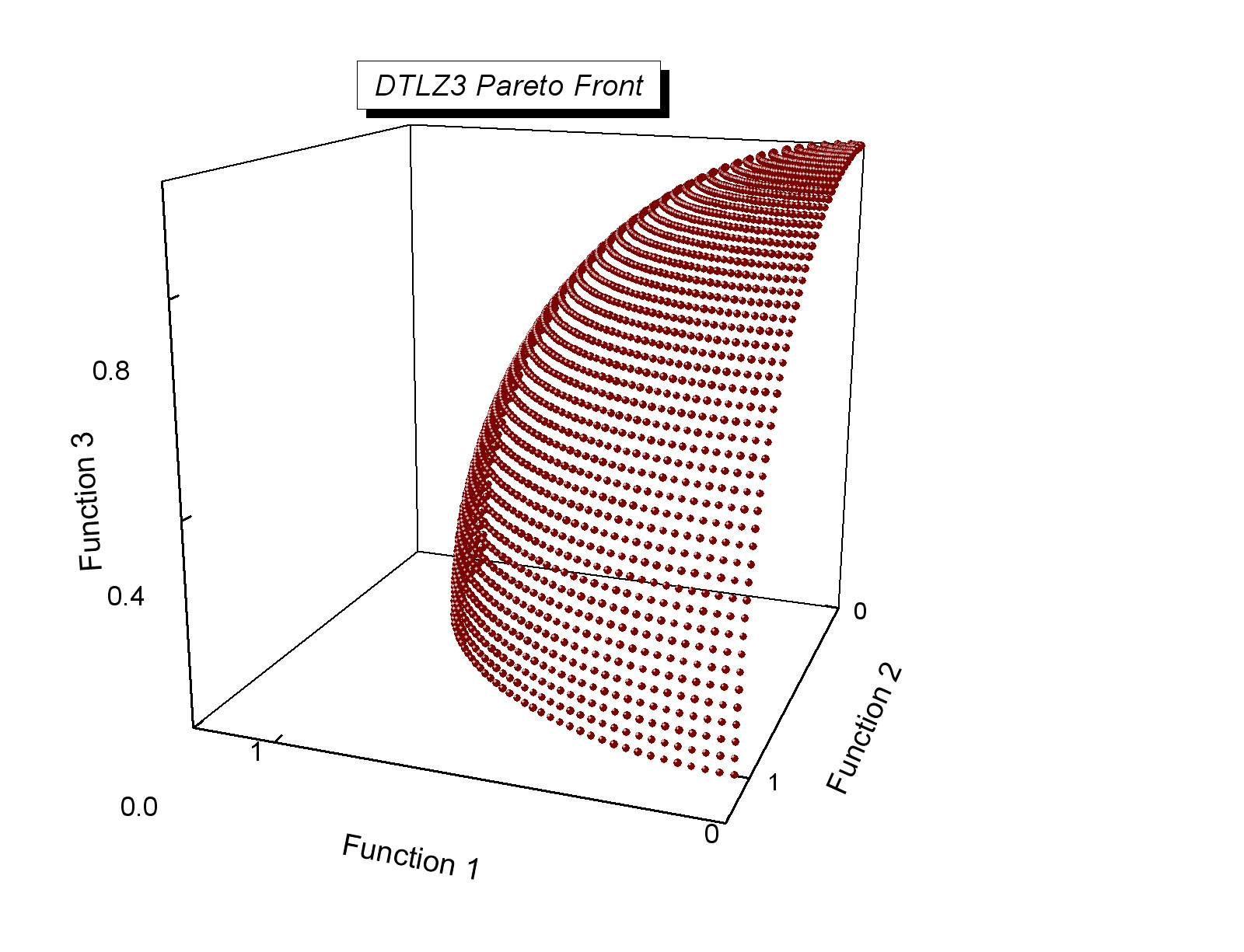 from Coello Coello, Lamont and Van Veldhuizen (2007) Evolutionary Algorithms for Solving Multi-Objective Problems, Second Edition. Springer Appendix E.
from Coello Coello, Lamont and Van Veldhuizen (2007) Evolutionary Algorithms for Solving Multi-Objective Problems, Second Edition. Springer Appendix E.New toolbox instance with the necessary components.
toolbox = base.Toolbox()
BOUND_LOW, BOUND_UP = 0.0, 1.0
toolbox.register("evaluate", lambda ind: benchmarks.dtlz3(ind, 2))
Describing attributes, individuals and population and defining the selection, mating and mutation operators.
toolbox.register("attr_float", uniform, BOUND_LOW, BOUND_UP, NDIM)
toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.attr_float)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("mate", tools.cxSimulatedBinaryBounded, low=BOUND_LOW, up=BOUND_UP, eta=20.0)
toolbox.register("mutate", tools.mutPolynomialBounded, low=BOUND_LOW, up=BOUND_UP, eta=20.0, indpb=1.0/NDIM)
toolbox.register("select", tools.selNSGA2)
Let's also use the toolbox to store other configuration parameters of the algorithm. This will show itself usefull when performing massive experiments.
toolbox.pop_size = 50
toolbox.max_gen = 500
toolbox.mut_prob = 0.2
A compact NSGA-II implementation
Storing all the required information in the toolbox and using DEAP's algorithms.eaMuPlusLambda function allows us to create a very compact -albeit not a 100% exact copy of the original- implementation of NSGA-II.
def nsga_ii(toolbox, stats=None, verbose=False):
pop = toolbox.population(n=toolbox.pop_size)
pop = toolbox.select(pop, len(pop))
return algorithms.eaMuPlusLambda(pop, toolbox, mu=toolbox.pop_size,
lambda_=toolbox.pop_size,
cxpb=1-toolbox.mut_prob,
mutpb=toolbox.mut_prob,
stats=stats,
ngen=toolbox.max_gen,
verbose=verbose)
Running the algorithm
We are now ready to run our NSGA-II.
%time res, logbook = nsga_ii(toolbox)
We can now get the Pareto fronts in the results (res).
fronts = tools.emo.sortLogNondominated(res, len(res))
Resulting Pareto fronts
plot_colors = ('b','r', 'g', 'm', 'y', 'k', 'c')
fig, ax = plt.subplots(1, figsize=(4,4))
for i,inds in enumerate(fronts):
par = [toolbox.evaluate(ind) for ind in inds]
df = pd.DataFrame(par)
df.plot(ax=ax, kind='scatter', label='Front ' + str(i+1),
x=df.columns[0], y=df.columns[1],
color=plot_colors[i % len(plot_colors)])
plt.xlabel('$f_1(\mathbf{x})$');plt.ylabel('$f_2(\mathbf{x})$');

- It is better to make an animated plot of the evolution as it takes place.
Animating the evolutionary process
We create a stats to store the individuals not only their objective function values.
stats = tools.Statistics()
stats.register("pop", copy.deepcopy)
toolbox.max_gen = 4000 # we need more generations!
Re-run the algorithm to get the data necessary for plotting.
%time res, logbook = nsga_ii(toolbox, stats=stats)
from JSAnimation import IPython_display
import matplotlib.colors as colors
from matplotlib import animation
def animate(frame_index, logbook):
'Updates all plots to match frame _i_ of the animation.'
ax.clear()
fronts = tools.emo.sortLogNondominated(logbook.select('pop')[frame_index],
len(logbook.select('pop')[frame_index]))
for i,inds in enumerate(fronts):
par = [toolbox.evaluate(ind) for ind in inds]
df = pd.DataFrame(par)
df.plot(ax=ax, kind='scatter', label='Front ' + str(i+1),
x=df.columns[0], y =df.columns[1], alpha=0.47,
color=plot_colors[i % len(plot_colors)])
ax.set_title('$t=$' + str(frame_index))
ax.set_xlabel('$f_1(\mathbf{x})$');ax.set_ylabel('$f_2(\mathbf{x})$')
return None
fig = plt.figure(figsize=(4,4))
ax = fig.gca()
anim = animation.FuncAnimation(fig, lambda i: animate(i, logbook),
frames=len(logbook), interval=60,
blit=True)
anim
The previous animation makes the notebook too big for online viewing. To circumvent this, it is better to save the animation as video and (manually) upload it to YouTube.
anim.save('nsgaii-dtlz3.mp4', fps=15, bitrate=-1, dpi=500)
from IPython.display import YouTubeVideo
YouTubeVideo('Cm7r4cJq59s')
Here it is clearly visible how the algorithm "jumps" from one local-optimum to a better one as evolution takes place.
MOP benchmark problem toolkits
Each problem instance is meant to test the algorithms with regard with a given feature: local optima, convexity, discontinuity, bias, or a combination of them.
- ZDT1-6: Two-objective problems with a fixed number of decision variables.
- E. Zitzler, K. Deb, and L. Thiele. Comparison of Multiobjective Evolutionary Algorithms: Empirical Results. Evolutionary Computation, 8(2):173-195, 2000. (pdf)
- DTLZ1-7: $m$-objective problems with $n$ variables.
- K. Deb, L. Thiele, M. Laumanns and E. Zitzler. Scalable Multi-Objective Optimization Test Problems. CEC 2002, p. 825 - 830, IEEE Press, 2002. (pdf)
- CEC'09: Two- and three- objective problems that very complex Pareto sets.
- Zhang, Q., Zhou, A., Zhao, S., & Suganthan, P. N. (2009). Multiobjective optimization test instances for the CEC 2009 special session and competition. In 2009 IEEE Congress on Evolutionary Computation (pp. 1–30). (pdf)
- WFG1-9: $m$-objective problems with $n$ variables, very complex.
- Huband, S., Hingston, P., Barone, L., & While, L. (2006). A review of multiobjective test problems and a scalable test problem toolkit. IEEE Transactions on Evolutionary Computation, 10(5), 477–506. doi:10.1109/TEVC.2005.861417
DEAP still lacks some of these problems so I will grab the DTLZ5, DTLZ6 and DTLZ7 problems from inspyred and adapt them for DEAP.
Note to self: send these problems to the DEAP guys.
DTLZ5 and DTLZ6 have an $m-1$-dimensional Pareto-optimal front.
- This means that in 3D the Pareto optimal front is a 2D curve.

- In two dimensions the front is a point.
def dtlz5(ind, n_objs):
from functools import reduce
g = lambda x: sum([(a - 0.5)**2 for a in x])
gval = g(ind[n_objs-1:])
theta = lambda x: math.pi / (4.0 * (1 + gval)) * (1 + 2 * gval * x)
fit = [(1 + gval) * math.cos(math.pi / 2.0 * ind[0]) *
reduce(lambda x,y: x*y, [math.cos(theta(a)) for a in ind[1:]])]
for m in reversed(range(1, n_objs)):
if m == 1:
fit.append((1 + gval) * math.sin(math.pi / 2.0 * ind[0]))
else:
fit.append((1 + gval) * math.cos(math.pi / 2.0 * ind[0]) *
reduce(lambda x,y: x*y, [math.cos(theta(a)) for a in ind[1:m-1]], 1) *
math.sin(theta(ind[m-1])))
return fit
def dtlz6(ind, n_objs):
from functools import reduce
gval = sum([a**0.1 for a in ind[n_objs-1:]])
theta = lambda x: math.pi / (4.0 * (1 + gval)) * (1 + 2 * gval * x)
fit = [(1 + gval) * math.cos(math.pi / 2.0 * ind[0]) *
reduce(lambda x,y: x*y, [math.cos(theta(a)) for a in ind[1:]])]
for m in reversed(range(1, n_objs)):
if m == 1:
fit.append((1 + gval) * math.sin(math.pi / 2.0 * ind[0]))
else:
fit.append((1 + gval) * math.cos(math.pi / 2.0 * ind[0]) *
reduce(lambda x,y: x*y, [math.cos(theta(a)) for a in ind[1:m-1]], 1) *
math.sin(theta(ind[m-1])))
return fit
DTLZ7 has many disconnected Pareto-optimal fronts.

def dtlz7(ind, n_objs):
gval = 1 + 9.0 / len(ind[n_objs-1:]) * sum([a for a in ind[n_objs-1:]])
fit = [ind for ind in ind[:n_objs-1]]
fit.append((1 + gval) * (n_objs - sum([a / (1.0 + gval) * (1 + math.sin(3 * math.pi * a)) for a in ind[:n_objs-1]])))
return fit
How does our NSGA-II behaves when faced with different benchmark problems?
problem_instances = {'ZDT1': benchmarks.zdt1, 'ZDT2': benchmarks.zdt2,
'ZDT3': benchmarks.zdt3, 'ZDT4': benchmarks.zdt4,
'DTLZ1': lambda ind: benchmarks.dtlz1(ind,2),
'DTLZ2': lambda ind: benchmarks.dtlz2(ind,2),
'DTLZ3': lambda ind: benchmarks.dtlz3(ind,2),
'DTLZ4': lambda ind: benchmarks.dtlz4(ind,2, 100),
'DTLZ5': lambda ind: dtlz5(ind,2),
'DTLZ6': lambda ind: dtlz6(ind,2),
'DTLZ7': lambda ind: dtlz7(ind,2)}
toolbox.max_gen = 1000
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("obj_vals", np.copy)
def run_problem(toolbox, problem):
toolbox.register('evaluate', problem)
return nsga_ii(toolbox, stats=stats)
Running NSGA-II solving all problems. Now it takes longer.
%time results = {problem: run_problem(toolbox, problem_instances[problem]) \
for problem in problem_instances}
Creating this animation takes more programming effort.
class MultiProblemAnimation:
def init(self, fig, results):
self.results = results
self.axs = [fig.add_subplot(3,4,i+1) for i in range(len(results))]
self.plots =[]
for i, problem in enumerate(sorted(results)):
(res, logbook) = self.results[problem]
pop = pd.DataFrame(data=logbook.select('obj_vals')[0])
plot = self.axs[i].plot(pop[0], pop[1], 'b.', alpha=0.47)[0]
self.plots.append(plot)
fig.tight_layout()
def animate(self, t):
'Updates all plots to match frame _i_ of the animation.'
for i, problem in enumerate(sorted(results)):
#self.axs[i].clear()
(res, logbook) = self.results[problem]
pop = pd.DataFrame(data=logbook.select('obj_vals')[t])
self.plots[i].set_data(pop[0], pop[1])
self.axs[i].set_title(problem + '; $t=' + str(t)+'$')
self.axs[i].set_xlim((0, max(1,pop.max()[0])))
self.axs[i].set_ylim((0, max(1,pop.max()[1])))
return self.axs
mpa = MultiProblemAnimation()
fig = plt.figure(figsize=(14,6))
anim = animation.FuncAnimation(fig, mpa.animate, init_func=mpa.init(fig,results),
frames=toolbox.max_gen, interval=60, blit=True)
anim
Saving the animation as video and uploading it to YouTube.
anim.save('nsgaii-benchmarks.mp4', fps=15, bitrate=-1, dpi=500)
YouTubeVideo('8t-aWcpDH0U')
- It is interesting how the algorithm deals with each problem: clearly some problems are harder than others.
- In some cases it "hits" the Pareto front and then slowly explores it.
Experiment design and reporting results
- Watching an animation of an EMO algorithm solve a problem is certainly fun.
- It also allows us to understand many particularities of the problem being solved.
- But, as Carlos Coello would say, we are not in an art appreciation class.
- We should follow the key concepts provided by the scientific method.
- I urge you to study the experimental design topic in depth, as it is an essential knowledge.
We need to evaluate performance
- Closeness to the Pareto-optimal front.
- Diversity of solutions.
- Coverage of the Pareto-optimal fronts.


Formalization of the hypervolume
For a set of solutions $\set{A}$, $$ I_\mathrm{hyp}\left(\set{A}\right) = \mathrm{volume}\left( \bigcup_{\forall \vec{a}\in\set{A}}{\mathrm{hypercube}(\vec{a},\vec{r})}\right)\,. $$
- We need a reference point, $\vec{r}$.
- Hypervolume is Pareto compliant (Fleischer, 2003): for sets $\set{A}$ and $\set{B}$, $\set{A}\dom\set{B} \implies I_\mathrm{hyp}(A)>I_\mathrm{hyp}(B)$.
- Calculating hypervolume is #P-hard, i.e. superpolynomial runtime unless P = NP (Bringmann and Friedrich, 2008).
An illustrative simple/sample experiment
Let's make a relatively simple experiment:
- Hypothesis: The mutation probability of NSGA-II matters when solving the DTLZ3 problem.
- Procedure: We must perform an experiment testing different mutation probabilities while keeping the other parameters constant.
Notation
As usual we need to establish some notation:
- Multi-objective problem (or just problem): A multi-objective optimization problem, as defined above.
- MOEA: An evolutionary computation method used to solve multi-objective problems.
- Experiment: a combination of problem and MOEA and a set of values of their parameters.
- Experiment run: The result of running an experiment.
- We will use
toolboxinstances to define experiments.
We start by creating a toolbox that will contain the configuration that will be shared across all experiments.
toolbox = base.Toolbox()
BOUND_LOW, BOUND_UP = 0.0, 1.0
NDIM = 30
# the explanation of this... a few lines bellow
def eval_helper(ind):
return benchmarks.dtlz3(ind, 2)
toolbox.register("evaluate", eval_helper)
def uniform(low, up, size=None):
try:
return [random.uniform(a, b) for a, b in zip(low, up)]
except TypeError:
return [random.uniform(a, b) for a, b in zip([low] * size, [up] * size)]
toolbox.register("attr_float", uniform, BOUND_LOW, BOUND_UP, NDIM)
toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.attr_float)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("mate", tools.cxSimulatedBinaryBounded, low=BOUND_LOW, up=BOUND_UP, eta=20.0)
toolbox.register("mutate", tools.mutPolynomialBounded, low=BOUND_LOW, up=BOUND_UP, eta=20.0, indpb=1.0/NDIM)
toolbox.register("select", tools.selNSGA2)
toolbox.pop_size = 200
toolbox.max_gen = 500
We add a experiment_name to toolbox that we will fill up later on.
toolbox.experiment_name = "$P_\mathrm{mut}="
We can now replicate this toolbox instance and then modify the mutation probabilities.
mut_probs = (0.05, 0.15, 0.3)
number_of_experiments = len(mut_probs)
toolboxes=list([copy.copy(toolbox) for _ in range(number_of_experiments)])
Now toolboxes is a list of copies of the same toolbox. One for each experiment configuration (population size).
...but we still have to set the population sizes in the elements of toolboxes.
for i, toolbox in enumerate(toolboxes):
toolbox.mut_prob = mut_probs[i]
toolbox.experiment_name = toolbox.experiment_name + str(mut_probs[i]) +'$'
for toolbox in toolboxes:
print(toolbox.experiment_name, toolbox.mut_prob)
Experiment design
As we are dealing with stochastic methods their results should be reported relying on an statistical analysis.
- A given experiment (a
toolboxinstance in our case) should be repeated a sufficient amount of times. - In theory, the more runs the better, but how much in enough? In practice, we could say that about 30 runs is enough.
- The non-dominated fronts produced by each experiment run should be compared to each other.
- We have seen in class that a number of performance indicators, like the hypervolume, additive and multiplicative epsilon indicators, among others, have been proposed for that task.
- We can use statistical visualizations like box plots or violin plots to make a visual assessment of the indicator values produced in each run.
- We must apply a set of statistical hypothesis tests in order to reach an statistically valid judgment of the results of an algorithms.
Note: I personally like the number 42 as it is the answer to The Ultimate Question of Life, the Universe, and Everything.
number_of_runs = 42
Running experiments in parallel
As we are now solving more demanding problems it would be nice to make our algorithms to run in parallel and profit from modern multi-core CPUs.
- In DEAP it is very simple to parallelize an algorithm (if it has been properly programmed) by providing a parallel
map()function throu thetoolbox. - Local parallelization can be achieved using Python's
multiprocessingorconcurrent.futuresmodules. - Cluster parallelization can be achived using IPython Parallel or SCOOP, that seems to be recommended by the DEAP guys as it was part of it.
Note: You can have a very good summary about this issue in http://blog.liang2.tw/2014-handy-dist-computing/.
Progress feedback
- Another issue with these long experiments has to do being patient.
- A little bit of feedback on the experiment execution would be cool.
- We can use the integer progress bar from IPython widgets and report every time an experiment run is finished.
from IPython.html import widgets
from IPython.display import display
progress_bar = widgets.IntProgressWidget(description="Starting...",
max=len(toolboxes)*number_of_runs)
A side-effect of using process-based parallelization
Process-based parallelization based on multiprocessing requires that the parameters passed to map() be pickleable.
- The direct consequence is that
lambdafunctions can not be directly used. - This is will certainly ruin the party to all
lambdafans out there! -me included. - Hence we need to write some wrapper functions instead.
- But, that wrapper function can take care of filtering out dominated individuals in the results.
def run_algo_wrapper(toolboox):
result,a = nsga_ii(toolbox)
pareto_sets = tools.emo.sortLogNondominated(result, len(result))
return pareto_sets[0]
All set! Run the experiments...
This is not a perfect implementation but... works!
%%time
from multiprocessing import Pool
display(progress_bar)
results = {}
pool = Pool()
for toolbox in toolboxes:
results[toolbox.experiment_name] = pool.map(run_algo_wrapper, [toolbox] * number_of_runs)
progress_bar.value +=number_of_runs
progress_bar.description = "Finished %03d of %03d:" % (progress_bar.value, progress_bar.max)
As you can see, even this relatively small experiment took lots of time!
As running the experiments takes so long, lets save the results so we can use them whenever we want.
import pickle
pickle.dump(results, open('nsga_ii_dtlz3-results.pickle', 'wb'))
In case you need it, this file is included in the github repository.
To load the results we would just have to:
loaded_results = pickle.load(open('nsga_ii_dtlz3-results.pickle', 'rb'))
results = loaded_results # <-- uncomment if needed
results is a dictionary, but a pandas DataFrame is a more handy container for the results.
res = pd.DataFrame(results)
res.head()
A first glace at the results
a = res.applymap(lambda pop: [toolbox.evaluate(ind) for ind in pop])
plt.figure(figsize=(11,3))
for i, col in enumerate(a.columns):
plt.subplot(1, len(a.columns), i+1)
for pop in a[col]:
x = pd.DataFrame(data=pop)
plt.scatter(x[0], x[1], marker='.', alpha=0.5)
plt.title(col)

The local Pareto-optimal fronts are clearly visible!
Calculating performance indicators
- As already mentioned, we need to evaluate the quality of the solutions produced in every execution of the algorithm.
- We will use the hypervolumne indicator for that.
- We already filtered each population a leave only the non-dominated individuals.
Calculating the reference point: a point that is “worst” than any other individual in every objective.
def calculate_reference(results, epsilon=0.1):
alldata = np.concatenate(np.concatenate(results.values))
obj_vals = [toolbox.evaluate(ind) for ind in alldata]
return np.max(obj_vals, axis=0) + epsilon
reference = calculate_reference(res)
reference
We can now compute the hypervolume of the Pareto-optimal fronts yielded by each algorithm run.
import deap.benchmarks.tools as bt
hypervols = res.applymap(lambda pop: bt.hypervolume(pop, reference))
hypervols.head()
How can we interpret the indicators?
Option A: Tabular form
hypervols.describe()
Option B: Visualization
import seaborn
seaborn.set(style="whitegrid")
fig = plt.figure(figsize=(15,3))
plt.subplot(1,2,1, title='Violin plots of NSGA-II with $P_{\mathrm{mut}}$')
seaborn.violinplot(hypervols, alpha=0.74)
plt.ylabel('Hypervolume'); plt.xlabel('Mutation probabilities')
plt.subplot(1,2,2, title='Box plots of NSGA-II with $P_{\mathrm{mut}}$')
seaborn.boxplot(hypervols, alpha=0.74)
plt.ylabel('Hypervolume'); plt.xlabel('Mutation probabilities');

Option C: Statistical hypothesis test
- Choosing the correct statistical test is essential to properly report the results.
- Nonparametric statistics can lend a helping hand.
- Parametric statistics could be a better choice in some cases.
- Parametric statistics require that all data follow a known distribution (frequently a normal one).
- Some tests -like the normality test- can be apply to verify that data meet the parametric stats requirements.
- In my experience that is very unlikely that all your EMO result meet those characteristics.
We start by writing a function that helps us tabulate the results of the application of an statistical hypothesis test.
import itertools
import scipy.stats as stats
def compute_stat_matrix(data, stat_func, alpha=0.05):
'''A function that applies `stat_func` to all combinations of columns in `data`.
Returns a squared matrix with the p-values'''
p_values = pd.DataFrame(columns=data.columns, index=data.columns)
for a,b in itertools.combinations(data.columns,2):
s,p = stat_func(data[a], data[b])
p_values[a].ix[b] = p
p_values[b].ix[a] = p
return p_values
The Kruskal-Wallis H-test tests the null hypothesis that the population median of all of the groups are equal.
- It is a non-parametric version of ANOVA.
- The test works on 2 or more independent samples, which may have different sizes.
- Note that rejecting the null hypothesis does not indicate which of the groups differs.
- Post-hoc comparisons between groups are required to determine which groups are different.
stats.kruskal(*[hypervols[col] for col in hypervols.columns])
We now can assert that the results are not the same but which ones are different or similar to the others the others?
In case that the null hypothesis of the Kruskal-Wallis is rejected the Conover–Inman procedure (Conover, 1999, pp. 288-290) can be applied in a pairwise manner in order to determine if the results of one algorithm were significantly better than those of the other.
- Conover, W. J. (1999). Practical Nonparametric Statistics. John Wiley & Sons, New York, 3rd edition.
Note: If you want to get an extended summary of this method check out my PhD thesis.
def conover_inman_procedure(data, alpha=0.05):
num_runs = len(data)
num_algos = len(data.columns)
N = num_runs*num_algos
_,p_value = stats.kruskal(*[data[col] for col in data.columns])
ranked = stats.rankdata(np.concatenate([data[col] for col in data.columns]))
ranksums = []
for i in range(num_algos):
ranksums.append(np.sum(ranked[num_runs*i:num_runs*(i+1)]))
S_sq = (np.sum(ranked**2) - N*((N+1)**2)/4)/(N-1)
right_side = stats.t.cdf(1-(alpha/2), N-num_algos) * \
math.sqrt((S_sq*((N-1-p_value)/(N-1)))*2/num_runs)
res = pd.DataFrame(columns=data.columns, index=data.columns)
for i,j in itertools.combinations(np.arange(num_algos),2):
res[res.columns[i]].ix[j] = abs(ranksums[i] - ranksums[j]/num_runs) > right_side
res[res.columns[j]].ix[i] = abs(ranksums[i] - ranksums[j]/num_runs) > right_side
return res
conover_inman_procedure(hypervols)
We now know in what cases the difference is sufficient as to say that one result is better than the other.
Another alternative is the Friedman test.
- Its null hypothesis that repeated measurements of the same individuals have the same distribution.
- It is often used to test for consistency among measurements obtained in different ways.
- For example, if two measurement techniques are used on the same set of individuals, the Friedman test can be used to determine if the two measurement techniques are consistent.
hyp_transp = hypervols.transpose()
measurements = [list(hyp_transp[col]) for col in hyp_transp.columns]
stats.friedmanchisquare(*measurements)
Mann–Whitney U test (also called the Mann–Whitney–Wilcoxon (MWW), Wilcoxon rank-sum test (WRS), or Wilcoxon–Mann–Whitney test) is a nonparametric test of the null hypothesis that two populations are the same against an alternative hypothesis, especially that a particular population tends to have larger values than the other.
It has greater efficiency than the $t$-test on non-normal distributions, such as a mixture of normal distributions, and it is nearly as efficient as the $t$-test on normal distributions.
raw_p_values=compute_stat_matrix(hypervols, stats.mannwhitneyu)
raw_p_values
The familywise error rate (FWER) is the probability of making one or more false discoveries, or type I errors, among all the hypotheses when performing multiple hypotheses tests.
Example: When performing a test, there is a $\alpha$ chance of making a type I error. If we make $m$ tests, then the probability of making one type I error is $m\alpha$. Therefore, if an $\alpha=0.05$ is used and 5 pairwise comparisons are made, we will have a $5\times0.05 = 0.25$ chance of making a type I error.
- FWER procedures (such as the Bonferroni correction) exert a more stringent control over false discovery compared to False discovery rate controlling procedures.
- FWER controlling seek to reduce the probability of even one false discovery, as opposed to the expected proportion of false discoveries.
- Thus, FDR procedures have greater power at the cost of increased rates of type I errors, i.e., rejecting the null hypothesis of no effect when it should be accepted.
One of these corrections is the Šidák correction as it is less conservative than the Bonferroni correction: $$\alpha_{SID} = 1-(1-\alpha)^\frac{1}{m},$$ where $m$ is the number of tests.
- In our case $m$ is the number of combinations of algorithm configurations taken two at a time, $$ m = {\mathtt{number\_of\_experiments} \choose 2}. $$
- There are other corrections that can be used.
from scipy.misc import comb
alpha=0.05
alpha_sid = 1 - (1-alpha)**(1/comb(len(hypervols.columns), 2))
alpha_sid
Let's apply the corrected alpha to raw_p_values. If we have a cell with a True value that means that those two results are the same.
raw_p_values.applymap(lambda value: value <= alpha_sid)
Further -and highly recommended- reading
- Cohen, P. R. (1995). Empirical Methods for Artificial Intelligence (Vol. 139). Cambridge: MIT press. link
- Bartz-Beielstein, Thomas (2006). Experimental Research in Evolutionary Computation: The New Experimentalism. Springer link
- García, S., & Herrera, F. (2008). An Extension on “Statistical Comparisons of Classifiers over Multiple Data Sets” for all Pairwise Comparisons. Journal of Machine Learning Research, 9, 2677–2694. pdf
Current research directions
- Many-objective problems.
- What about using performance indicators for fitness assignment?
- SMS-EMOA, HypE, IBEA, etc.
- Make the variation smarter by including machine learning:
- MO-CMA-ES, MIDEA, MONEDA, MARTEDA, etc.
- Why not evolve sets instead of individuals?
- Set-based multi-objective optimization.
- Decomposition:
- MOEA/D.
- Preferences and interactivity
- r-NSGA-II, NSGA-III.
- Fitness landscapes.
Check out http://simco.gforge.inria.fr/doku.php?id=openproblems
Final remarks
In this class/notebook we have seen some key elements:
- The Pareto dominance relation in action.
- The NSGA-II algorithm.
- Some of the existing MOP benchmarks.
- How to perform experiments and draw statistically valid conclusions from them.
Bear in mind that:
- When working in EMO topics problems like those of the CEC'09 or WFG toolkits are usually involved.
- The issue of devising a proper experiment design and interpreting the results is a fundamental one.
- The experimental setup presented here can be used with little modifications to single-objective optimization and even to other machine learning or stochastic algorithms.
- No-free-lunch theorem.
What? No questions?
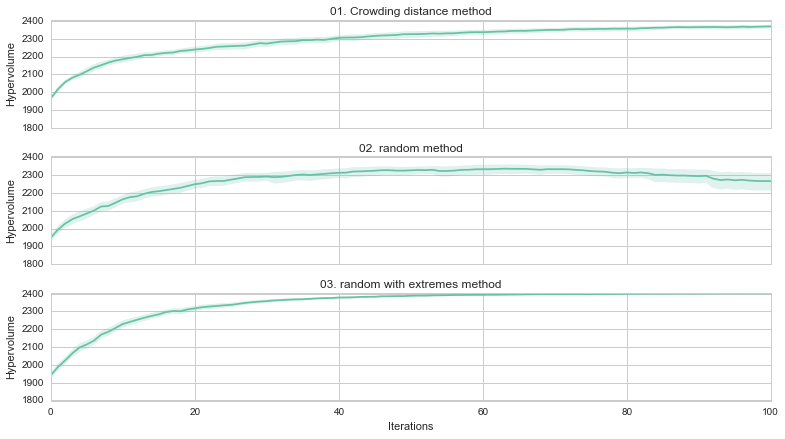
What is the key element of crowding distance?
What happens if we substitute crowding distance with other 'secondary' selection criterion?
Postscript
This IPython notebook can be found at the talk github repository:
This notebook is better viewed rendered as slides. You can convert it to slides and view them by:
- using nbconvert with a command like:
$ ipython nbconvert --to slides --post serve <this-notebook-name.ipynb> - installing Reveal.js - Jupyter/IPython Slideshow Extension
- using the online IPython notebook slide viewer (some slides of the notebook might not be properly rendered).